Distance correlation
In statistics and in probability theory, distance correlation is a measure of statistical dependence between two random variables or two random vectors of arbitrary, not necessarily equal dimension. Its important property is that this measure of dependence is zero if and only if the random variables are statistically independent. This measure is derived from a number of other quantities that are used in its specification, specifically: distance variance, distance standard deviation and distance covariance. These take the same roles as the ordinary moments with corresponding names in the specification of the Pearson product-moment correlation coefficient.
These distance-based measures can be put into an indirect relationship to the ordinary moments by an alternative formulation (described below) using ideas related to Brownian motion, and this has led to the use of names such as Brownian covariance and Brownian distance covariance.
Contents |
Background
The classical measure of dependence, the Pearson correlation coefficient,[1] is mainly sensitive to a linear relationship between two variables. Distance correlation was introduced in 2005 by Gabor J Szekely in several lectures to address this deficiency of Pearson’s correlation, namely that it can easily be zero for dependent variables. Correlation = 0 (uncorrelatedness) does not imply independence while distance correlation = 0 does imply independence. The first results on distance correlation were published in 2007 and 2009.[2][3] It was proved that distance covariance is the same as the Brownian covariance.[3] These measures are examples of energy distances.
Definitions
Distance covariance
The population value of distance covariance [2]:p.2783;[4] is the square root of
- dCov2(X,Y):= E|X – X'||Y – Y'| + E|X – X'| E|Y – Y'| – E|X – X'||Y – Y"| - E|X – X"||Y – Y'|
-
-
- = E|X – X'||Y – Y'| + E|X – X'| E|Y – Y'| – 2E|X – X'||Y – Y"|,
-
-
where E denotes expected value, |.| denotes Euclidean norm, and (X,Y), (X',Y'), and (X",Y") are independent and identically distributed. Distance covariance can be expressed in terms of Pearson’s covariance, cov, as follows: dCov2(X,Y) = cov(|X–X'|, |Y–Y'|) – 2cov(|X–X'|, |Y–Y"|). This identity shows that the distance covariance is not the same as the covariance of distances, cov(|X–X'|, |Y–Y'|), which can be zero even if X and Y are not independent.
The sample distance covariance is defined as follows. Let (Xk Yk), k=1,2,…, n be a statistical sample from a pair of real valued or vector valued random variables (X,Y). First, compute all pairwise distances
- ak,l = |Xk – Xl | and bk,l = |Yk – Yl | for k,l=1,2,…,n.
That is, compute the n by n distance matrices (ak,l) and (bk,l). Then take all centered distances Ak,l:= ak,l –ak.–a.l + a.. and Bk,l:= bk,l – bk. - b.l + b.. where ak. is the k-th row mean, a.l is the l-th column mean, and a.. is the grand mean of the distance matrix of the X sample. The notation is similar for the b values. (In the matrices of centered distances (Ak,l) and (Bk,l) all row sums and all column sums equal zero.) The squared sample distance covariance is simply the arithmetic average of the products Ak,l Bk,l; that is
- dcov2n (X,Y):= (1/n2) Σ k,l Ak,l Bk,l.
The statistic Tn = n[dcov2n (X,Y)] determines a consistent multivariate test of independence of random vectors in arbitrary dimensions. For an implementation see dcov.test function in the energy package for R.[5]
Distance variance
The distance variance is a special case of distance covariance when the two variables are identical. The population value of distance variance is the square root of
- dVar2(X):= E|X – X'|2 + E2|X – X'| – 2E|X – X'||X – X"|,
where E denotes the expected value, X’ is an independent and identically distributed copy of X and X" is independent of X and X' and has the same distribution as X and X'.
The sample distance variance is the square root of
- dvar2n (X):=dcov2n (X,X) = (1/n2) Σ k,l A k,l2,
which is a relative of Corrado Gini’s mean difference introduced in 1912 (but Gini did not work with centered distances).
Distance standard deviation
The distance standard deviation is the square root of the distance variance.
Distance correlation
The distance correlation [2][3] of two random variables is obtained by dividing their distance covariance by the product of their distance standard deviations. The distance correlation is
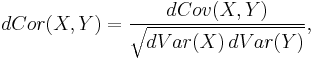
and the sample distance correlation is defined by substituting the sample distance covariance and distance variances for the population coefficients above.
For easy computation of sample distance correlation see the dcor function in the energy package for R.[5]
Properties
Distance correlation
(i) 0 ≤ dcorn(X,Y) ≤ 1 and 0 ≤ dCor(X,Y) ≤1.
(ii) dCor(X,Y) = 0 if and only if X and Y are independent.
(iii) dcorn(X,Y) = 1 implies that dimensions of the linear spaces spanned by X and Y samples respectively are almost surely equal and if we assume that these subspaces are equal, then in this subspace Y = a + b CX for some vector a, scalar b, and orthonormal matrix C.
Distance covariance
(i) dCov (X,Y) ≥ 0 and dcovn (X,Y) ≥ 0.
(ii) dCov2(a1 +b1 C1 X, a2 +b2 C2 Y) = |b1 b2| dCov2(X,Y) for all constant vectors a1, a2 , scalars b1, b2, and orthonormal matrices C1, C2.
(iii) If the random vectors (X1, Y1) and (X2, Y2) are independent then
- dCov(X1 +X2, Y1 +Y2) ≤ dCov(X1, Y1) + dCov (X2, Y2).
Equality holds if and only if X1 and Y1 are both constants, or X2 and Y2 are both constants, or X1, X2, Y1, Y2 are mutually independent.
(iv) dCov (X,Y) = 0 if and only if X and Y are independent.
This last property is the most important effect of working with centered distances.
The statistic dcov2n (X,Y) is a biased estimator of dCov2(X,Y) because E[dcov2n (X,Y)] = [(n-1)/n2][(n-2)dCov2(X,Y)+E|X-X’|E|Y-Y’|]. The bias therefore can easily be corrected.[6]
Distance variance
(i) dVar(X) = 0 if and only if X = E(X) almost surely.
(ii) dVarn (X) = 0 if and only if every sample observation is identical.
(iii) dVar(a + bCX) = |b| dVar(X) for all constant vectors a, scalars b, and orthonormal matrices C.
(iv) If X and Y are independent then dVar(X + Y) ≤ dVar(X) + dVar(Y).
Equality holds if (iv) if and only if one of the random variables X or Y is a constant.
Generalization
Distance covariance can be generalized to include powers of Euclidean distance. Define
- dCov2(X, Y; α):= E|X – X’|α|Y – Y’|α + E|X – X’|α E|Y – Y’|α – 2 E|X – X’|α|Y – Y"|α.
Then for every 0 < α < 2, X and Y are independent if and only if dCov2(X, Y; α) = 0. It is important to note that this characterization does not hold for exponent α = 2; in this case for bivariate (X, Y), dCor(X, Y; α=2) is a deterministic function of the Pearson correlation.[2] If ak,l and bk,l are α powers of the corresponding distances, 0 < α ≤ 2, then α sample distance covariance can be defined as the nonnegative number for which
- dcov2n (X,Y ; α):= (1/n2) Σ k,lAk,l Bk,l.
One can extend dCov to metric space valued random variables X and Y: ak,l = K(Xk, Xl) and bk,l = L(Yk, Yl) where K, L are squares of metrics and (strictly) negative definite continuous functions.
Alternative formulation: Brownian covariance
Brownian covariance is motivated by generalization of the notion of covariance to stochastic processes. The square of the covariance of random variables X and Y can be written in the following form:
![\operatorname{cov}(X,Y)^2 = \operatorname{E}\left[
\left(X - \operatorname{E}(X)\right)
\left(X^\mathrm{'} - \operatorname{E}(X^\mathrm{'})\right)
\left(Y - \operatorname{E}(Y)\right)
\left(Y^\mathrm{'} - \operatorname{E}(Y^\mathrm{'})\right)
\right]](/2012-wikipedia_en_all_nopic_01_2012/I/403e25a5e1921e5fecab492a0aff9cdb.png)
where E denotes the expected value and the prime denotes independent and identically distributed copies. We need the following generalization of this formula. If U(s), V(t) are arbitrary random processes defined for all real s and t then define the U-centered version of X by
![X_U�:= U(X) - \operatorname{E}_X\left[ U(X) \mid \left \{ U(t) \right \} \right]](/2012-wikipedia_en_all_nopic_01_2012/I/463c3aa29f78ab4a062b1b3be3face62.png)
whenever the subtracted conditional expected value exists and denote by YV the V-centered version of Y.[3][7][8] The (U,V) covariance of (X,Y) is defined as the nonnegative number whose square is
![\operatorname{cov}_{U,V}^2(X,Y)�:= \operatorname{E}\left[X_U X_U^\mathrm{'} Y_V Y_V^\mathrm{'}\right]](/2012-wikipedia_en_all_nopic_01_2012/I/916bc8c186c680e114bba41eb8a06f30.png)
whenever the right-hand side is nonnegative and finite. The most important example is when U and V are two-sided independent Brownian motions /Wiener processes with expectation zero and covariance |s| + |t| - |s-t| = 2 min(s,t). (This is twice the covariance of the standard Wiener process; here the factor 2 simplifies the computations.) In this case the (U,V) covariance is called Brownian covariance and is denoted by
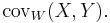
There is a surprising coincidence: The Brownian covariance is the same as the distance covariance:
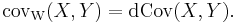
On the other hand, if we replace the Brownian motion with the deterministic identity function id then Covid(X,Y) is simply the absolute value of the classical Pearson covariance,
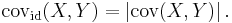
See also
- RV coefficient
- For a related third-order statistic, see Distance skewness.
Notes
References
- Bickel, P.J. and Xu, Y. (2009) "Discussion of: Brownian distance covariance", Annals of Applied Statistics, 3 (4), 1266–1269. doi:10.1214/09-AOAS312A Free access to article
- Gini, C. (1912). Variabilità e Mutabilità. Bologna: Tipografia di Paolo Cuppini.
- Pearson, K. (1895). "Note on regression and inheritance in the case of two parents", Proceedings of the Royal Society, 58, 240–242
- Pearson, K. (1920). "Notes on the history of correlation", Biometrika, 13, 25–45.
- Székely, G. J. Rizzo, M. L. and Bakirov, N. K. (2007). "Measuring and testing independence by correlation of distances", Annals of Statistics, 35/6, 2769–2794. doi: 10.1214/009053607000000505 Reprint
- Székely, G. J. and Rizzo, M. L. (2009). "Brownian distance covariance", Annals of Applied Statistics, 3/4, 1233–1303. doi: 10.1214/09-AOAS312 Reprint
- Kosorok, M. R. (2009) "Discussion of: Brownian Distance Covariance", Annals of Applied Statistics, 3/4, 1270–1278. doi:10.1214/09-AOAS312B Free access to article